
目录
本文专注于 Optimisim 的架构学习和思考,是第一篇,希望从 OP 入手,逐渐拓展对 Rollup、二层网络等方案的理解。
在前面写过一些列文章涉及了常见的共识协议,如 HotStuff,Tendermint 等传统 BFT 共识以及更为综合和现代的以太坊 Gasper,在学习了它们后,我对 Rollup 这种二层网络有另一个观察角度。
在开发一条公链并设计共识模块时,我们当然可以选择成熟的共识协议或 SDK 比如 Cosmos,但如果我希望直接让现有的公链帮我们的公链做共识,同时实现 Safety、Liveness、Responsiveness 等特性,这个交互协议要如何进行设计?这是一个有趣的思路,假设 Rollup 不是批量上报数据而是和 L1 出块频率保持一致,L2 就是一条使用以太坊做共识的普通公链罢了。这便是我理解的 Rollup 二层网络的底层逻辑。
理解 Layer2 和 Rollup
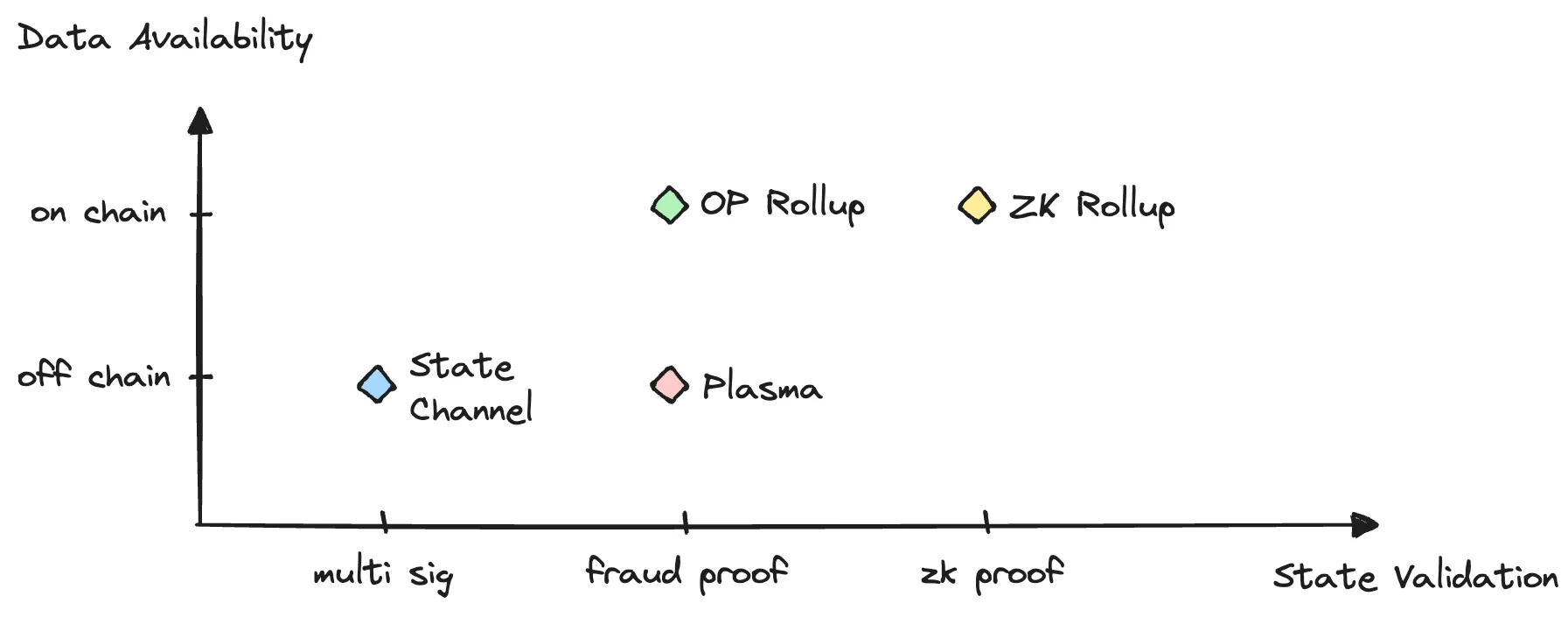
对于各种 Layer2 方案(后简称 L2),会出现两个指标需要我们关注。
- Data Availability:数据可用性,简称 DA,我们希望数据可以随时取用,故障后有能力进行恢复。这往往决定于 L2 交易数据的存储位置,State Channel 和 Plasma 等方案数据仅保存在 L2 上,而 Rollup 会将数据备份在 L1。
- State Validation:L2 状态的验证,我们需要保证 L2 的交易计算的正确性。通常包括多签、欺诈证明和零知识证明。
不考虑有争议的 Side Chain,目前的 L2 方案在这两个特性上所处的位置如下图。
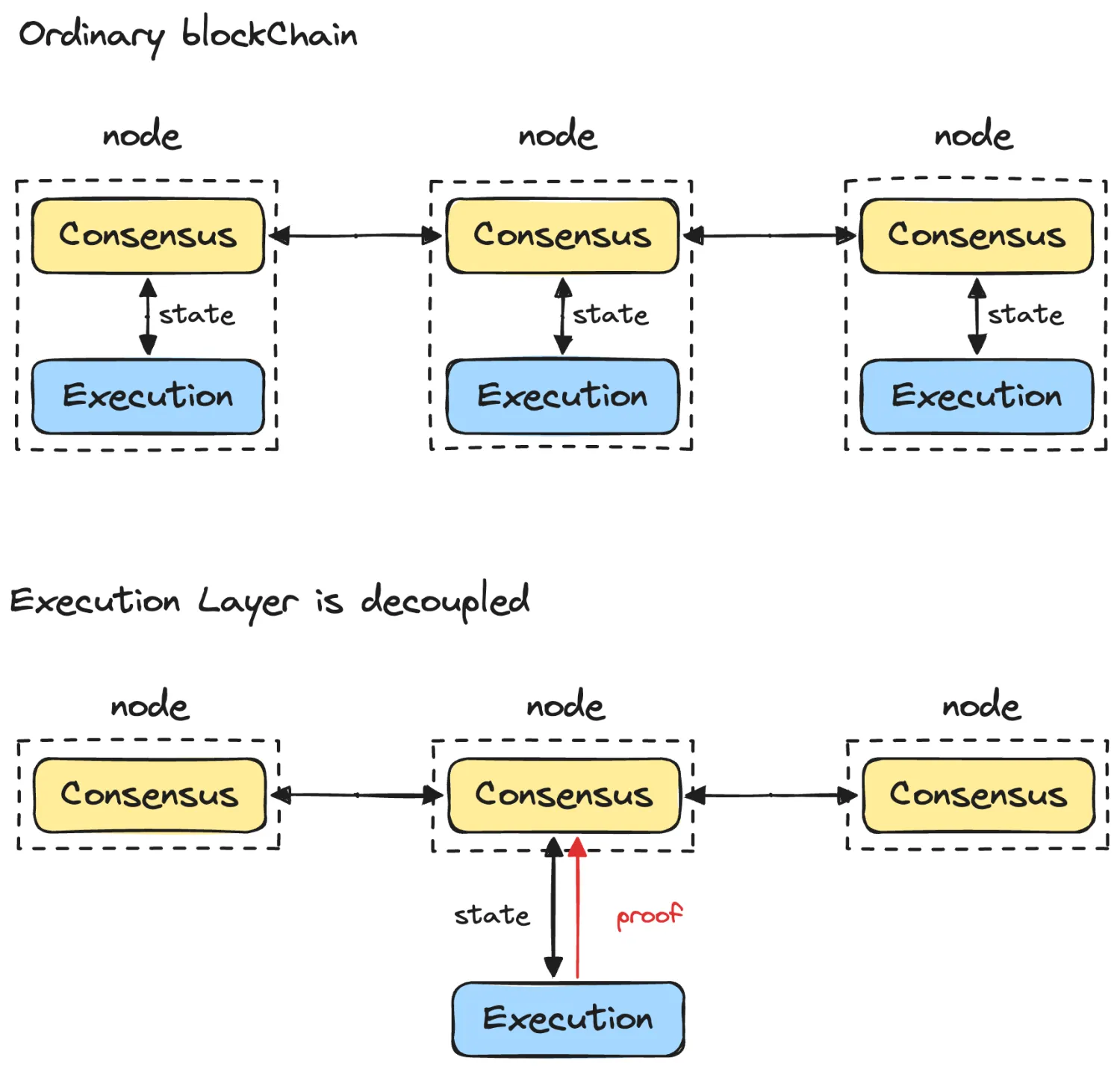
比特币、以太坊等公链之所以扩展性很低,是因为在一个去中心化网络中,交易的计算、存储、共识、传输成本都因资源受限而大幅提高,这主要是由于大量节点存在于网络中,随着这些节点的增加,相关的资源消耗也会变多。但其实交易的计算并没有什么必要放在 L1 上执行,L1 只需要对计算后的结果(即系统状态)达成共识,没有必要所有的 L1 节点都算一遍,这费时费力,是否可以让个别节点计算,并提供其计算结果是正确的证明。由此思路我们提出了诸多 L2 方案,希望将计算过程搬移到线下执行。
进一步思考,计算过程并不需要所有节点都参与进来,那计算层和共识层势必分离,再通过某种协议进行整合,这种模块化的区块链实现方式不仅更为灵活,而且更加经济。如下图。
说远了。
Rollup 是遵循这个解决思路的方案之一,其最大的特点是,Rollup 不仅仅充当了 L1 的计算层从而提升其可扩展性,同时还会备份交易数据到 L1 上,这使得 L1 不仅保存一个状态的计算结果,也存有真实的交易数据,这样即使 L2 崩溃也可以随时恢复,保证了 DA。L2 Chain 可以从 L1 Chain 中完整地派生出来,这是 Rollup 最大特点,可以表现为:
derive_rollup_chain(l1_blockchain) -> rollup_blockchain
既然 Rollup 替 L1 进行了计算,那么这里就涉及到了信任的问题,Rollup 如何证明自己的计算是正确的。针对这个问题目前有两种解决思路,一个是提供正向证明,证明自己计算确实准确无误,这里主要是零知识证明,对应的 Rollup 称为 ZK Rollup,另一个思路是提供反向证明,即欺诈证明,需要挑战者证明这个计算是错误的,这种情况默认计算正确,因此称为 Optimistic Rollup。而 Optimism 就是 Optimistic Rollup 的一个代表项目,其 OP Stack 不仅实现了 OP Mainnet,也是 Base、Unichain 等二层项目的底层架构。
对于 Rollup,我们可以将 L2 看做 L1 的计算层,也可能将 L1 看做 L2 的共识层和 DA 层,这取决于观察视角。总之不难猜测,Rollup 大约就是接收用户交易,完成计算,仅将计算结果发送给 L1 进行共识,同时上报具体的交易数据保证 DA。
理解 Optimism 架构
基本结构
一个可用的 Rollup 项目,必须能对用户进行交易的处理,只不过除了类似 L1 的普通交易之外,还包括了存款交易(Deposit Tx)和提现交易(Withdrawal Tx)。
OP Rollup 中往往会抽象出两个角色,Sequencer 和 Verifier,其中:
- Sequencer: 负责不断派生 L2 区块,使用 L1 作为共识层和 DA 层,以保证 L2 状态的 Safety、Liveness 和 DA 等特性。
- Verifier:负责对 L2 当前状态是否计算正确进行验证,保证 L2 数据真实合法,以供 L1 使用。
Optimism 划分了诸多模块以实现 Sequencer 和 Verifier 的功能,包括:
- Rollup Node: 负责根据 L1 对 L2 区块进行派生(Derivation)。Rollup Node 对应代码中的 op-node 模块。
- Execution Layer(后简称 EL): 负责 L2 中交易的计算和执行,它和 Rollup Node 就分别像区块链中的计算层和共识层。EL 对应代码中的 op-geth 模块,顾名思义,它基于以太坊 geth 代码,最大程度的保证与以太坊计算层兼容。
- Batcher:负责发送压缩后的交易到 L1 以保证 Data Availability。Batcher 对应代码中的 op-batcher 模块。
- Proposer:负责发送 L2 的状态到 L1 以实现 L1 对 L2 数据的使用。Proposer 对应代码中的 op-proposer 模块。
Rollup Node 使用两种模式分别实现了 Sequencer 和 Verifier,其中 Rollup Node(Sequencer Mode) + EL + Batcher + Proposer 构成了 Sequencer,而 Rollup Node(Verifier Mode) + EL 构成了 Verifier。OP 的架构图如下:
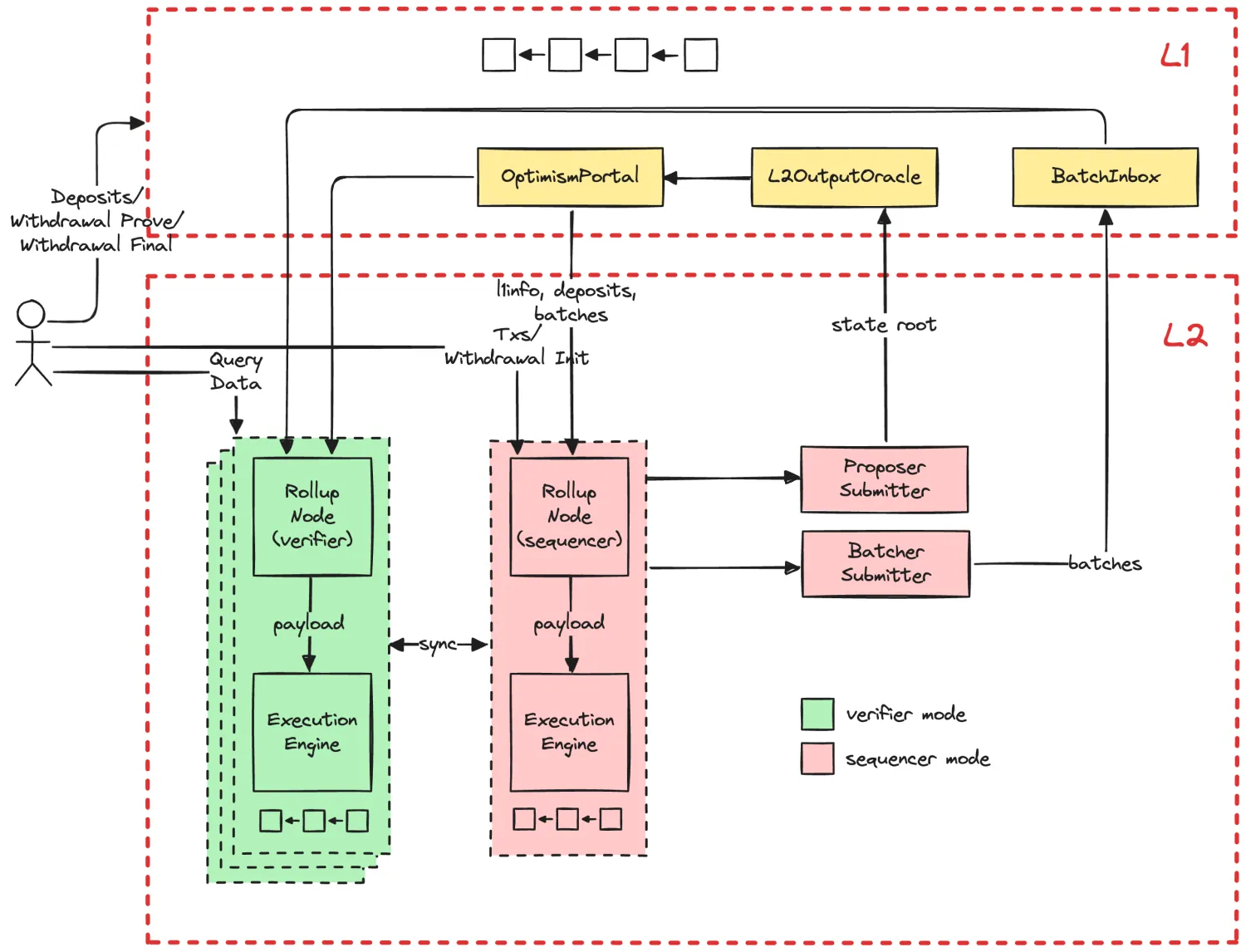
目前请仅看下这张图中的模块划分,其他部分如黄色区域以及箭头走向暂不解释。图中可以看出如下几点:
- L2 存在多个 Verifiers,而目前仅有一个 Sequencer。
- L2 Node + Proposer + Batcher 共同承担了 Sequencer 的职责。
- L2 与 L1 之间会进行数据交互,L2 Node 之间也会进行数据同步。
L1 Chain 和 L2 Chain 的关系
L2 区块状态
L1 和 L2 都有自己的区块链,它们分别打包了各自交易处理的历史记录。区块拥有不同的状态,对于 L1(Ethereum)来说,区块的状态基本可分为 unfinalized 和 finalized,完成 finalized 的区块表示无法被回滚,因此可以抵抗 Long Range Attack 之类的攻击,具体内容可参考以太坊的 PoS 这篇文章。而 L2 的区块状态有三种:
- unsafe: 仅在 L2 Chain 上产生,并没有在 L1 上完成共识。
- safe: 已经在 L1 上完成了共识,但对应的 L1 Block 还没有 finalized。
- finalized: 与 L1 一样,L2 Block 被 finalized 表示该区块不可回滚。这需要满足两个条件:对应的 L1 Block 已经 finalized 和 L2 Block 平安度过挑战期(即其状态的正确性被证明)
这里需要注意的一点是,我们通常习惯了「出块」即代表完成了共识,但 L2 的 unsafe block 其实并没有完成共识,更确切的说只是一个提案 proposal。不过为了和 Optimism 相关资料保持一致,这里还是将 unsafe block 称作区块,当完成共识后更改为 safe 状态。
如同上文所说,对于 L1 和 L2 的关系我们可以换一个视角,不在把 L2 看做是 L1 的计算层,而是把 L1 看做是 L2 的共识层。当 L2 率先出块后(产出 unsafe block),我们会将其发送给 L1 进行共识,L1 完成共识之后会告知 L2,这样才算完成整个交易执行的过程。这里注意两点:
- L1 无法主动通知 L2,因此只能 L2 通过轮训的方式时刻查询 L1 状态。
- L2 出块数量远大于 L1,所以无法做到每一个 L2 区块都要立刻发送给 L1 做共识,而是凑够多个区块一并发送,类似于数据库的 Group Commit。这在解耦计算层的基础上又进一步提高了吞吐量,当然也增加了交易时延。
L1 Sequencing Window 和 L2 Sequencing Epoch
L2 收集一定数量的 unsafe block 到提交至 L1 的时间段称为一个 Sequencing Epoch,这个 epoch 并非以太坊上的 epoch,后者是固定 32 个 slot,L1 和 L2 之间传输的永远是单个 Sequencing Epoch 的区块数量。很显然,我们对 L2 的 epoch 长度选择应该有一个说法,比如是否要参考 L1 的 epoch 使用固定数量的 L2 Blocks 作为一个 Sequencing Epoch 呢?
这里就要探究 Sequencing Epoch 的意义是什么。
Sequencing Epoch 的意义是,对于该 epoch 中所有的 L2 Blocks 都可以作为一个批次,一次性的由 L1 完成共识。我们不妨假设 L2 的 epoch 是固定数量的,比如 10 个区块,由于 L1 是可以跳过 slot 而没有出块的,这就可能会出现 L2 的某一个 epoch 还没有被共识而新的 epoch 又要被提交的情况。因此 L2 的 epoch 应当受 L1 约束,而不能完全独立自由的选择自己的长度。这个约束是 L1 要求的一个 Timeout,即某个 L2 的 epoch 必须在 L1 出块一定数量的 Block 之前提交给 L1,否则则被认为无效,L1 的这段区间被称为 Sequencing Window。同时,L2 的 Epoch Number 也被设置为与 L1 对应 Block Number 相同,比如 L2 上的 epoch N 是由 L1 上的 block N 生成的。
总结一下,L1 规定,L2 epoch N 所提交的数据,将会在 Sequencing Window 之后进行派生(即通知 L2 共识成功,更改 epoch N 的 unsafe blocks 状态),这就意味着 L2 epoch N 的 blocks 必须要在 L1 的 block N + SequencingWindowSize 块之前完成提交,否则 L1 将拒绝对这个 Epoch 的数据进行共识。Sequencing Window 是 L1 作为 L2 的共识层所要求的一个验证项,L1 只能接收对一个最近时间段内的 L2 Blocks 进行共识,超过了这个 Timeout 便会拒绝,过时不候。其实真正的因果关系是,由于有了 Sequencing Window,也就形成了 L2 上的一个个 epoch,提交一次即为一个 epoch。这就是 Sequencing Window 和 Sequencing Epoch 的设计意义。
下图中解释了 L1 Chain 和 L2 Chain 的同步关系,在 L2 中每一个 Epoch 都对应 L1 上的一个区块,比如 epoch N 源于 L1 上的 block N,当 epoch N 开始在 L2 上出块后,一定要在 block N+w 之前提交 epoch N 的计算结果到 L1 上 L1 才会接受,然后开启下一个 L2 的 epoch。图中默认了 epoch 刚好在 block N+w 时提交了epoch N 的交易计算结果,因此开启下一个 epoch N+w,但其实只要是在此之前都是可以的。
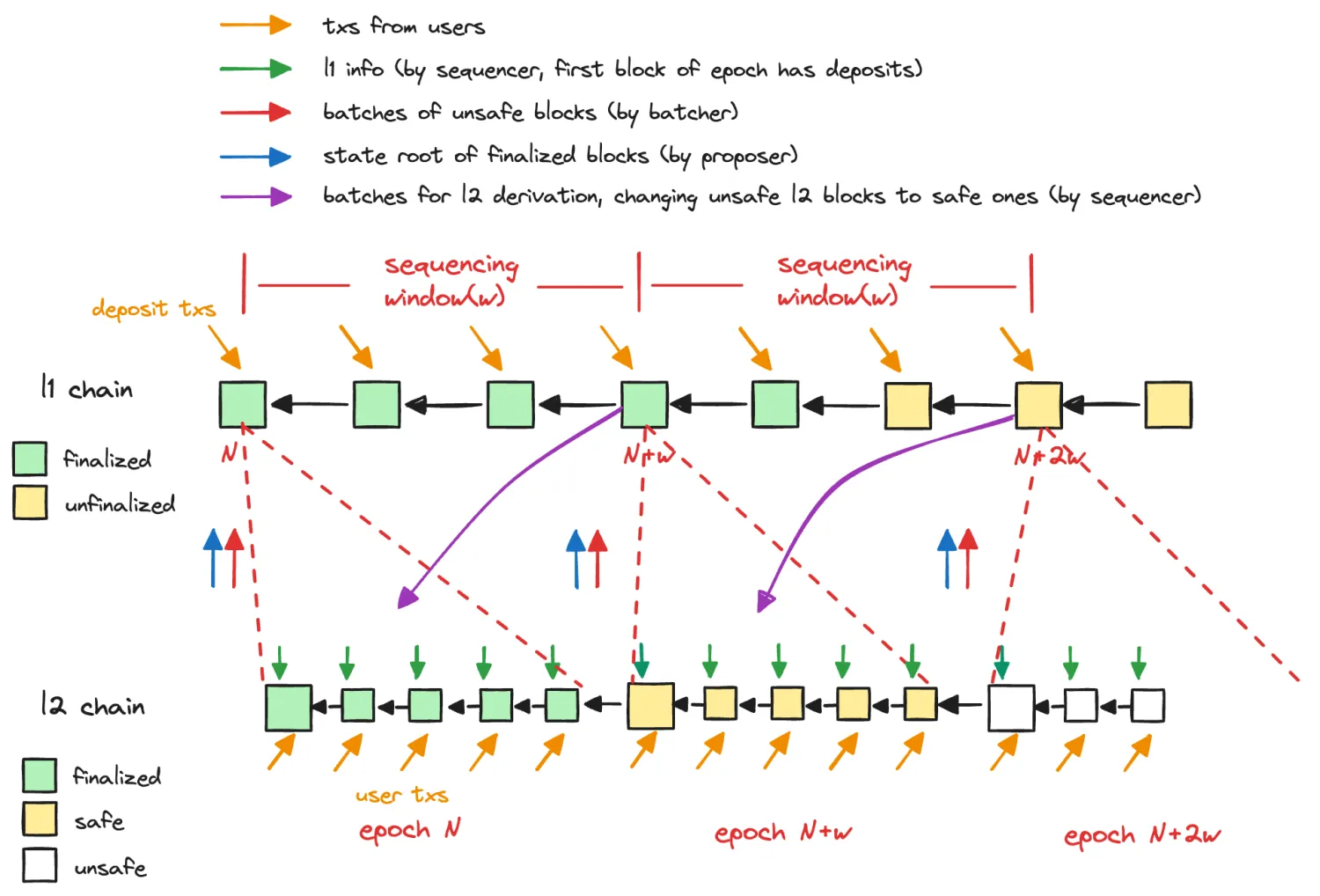
图中,当一个 epoch 持续出块之后,会在该 epoch 结尾处提交产生的 unsafe blocks 到 L1(batcher 提交交易记录,红色箭头),随后的 L1 Block 中会对计算结果进行共识,并完成 epoch N 的 L2 Blocks 的派生(紫色箭头),将 epoch N 区块的状态从 unsafe 变为 safe,并将已经 finalized 的 L1 Block 对应的,并且已经度过挑战期的 epoch 区块状态更新为 finalized。图中的 L2 Chain 分别使用绿色、黄色、和白色代表 finalized、safe、以及 unsafe 区块,而 L1 Chain 中最后一个 checkpoint 之前的区块均为 finalized(绿色),而后面的黄色区块还未 finalize。另外,蓝色箭头表示 L2 会提交 State Root 给 L1,不过这个 State Root 仅针对已经 Finalized 的 L2 Block 来说。未 finalized 的 L2 Block 不会提交 State Root 给 L1,因为无法确定该 State Root 是否还会变化。通过这样一种机制,L2 上的区块可以实时和 L1 上区块的状态保持同步,并使用 L1 完成对于 L2 交易的高效共识。
总结如下:
- L2 Chain 被划分为不同的 epoch,每一个 epoch 对应一个 L1 Block。
- 对于以太坊 L1 中的某个区块编号 N,在 L2 Chain 上存在一个对应的 epoch 编号 N。
- 这个对应关系并不是立即产生的。L2 Chain 上的 epoch 编号 N 只有在 sequencing window 时间窗结束之后才能确定,即需要等待 L1 区块编号
N + SequencingWindowSize被加入 L1 Chain 之后,L2 的这个 epoch 才能被正式确立。 - 每个 epoch 至少包含一个 L2 区块。这些区块中会包含与 L1 相关的上下文信息,比如区块哈希和时间戳。
- 每个 epoch 中的第一个区块会包含通过 L1 上的 OptimismPortal 合约发起的所有存款(deposits)。
- 每个 L2 区块还可能包含直接提交给 Sequencer(排序者)的交易(即 Sequenced Transactions,用户直接向 L2 发送的交易)。
- Sequencer 负责生成 L2 区块。当 Sequencer 为某个 epoch 创建新的 L2 区块时,它必须在该 epoch 的时间窗口内,将这些区块提交到 L1 中。这意味着,所有属于 epoch N 的 L2 区块必须在 L1 区块编号
N + SequencingWindowSize之前被提交。 - 这些提交的 L2 区块的批次(batch)和 L1 上的
TransactionDeposited事件一起,用于从 L1 Chain 派生出 L2 Chain 的状态。
L2 和 L1 有点像内存和磁盘,所有的交易在内存中保存,但磁盘中也进行了持久化,这样即使内存中的数据全部丢失,也可以从磁盘当中恢复。所有的计算在内存中进行,定期 Group Commit 到磁盘(L1)中。我们要解决的问题就是,由于去中心化,L2 在 L1 眼中默认是不可信的,那么如何保证内存(L2)与磁盘(L1)的数据一致性并证明数据的正确性。
L1 对于 L2 有两个作用,一个是作为 L2 的共识模块,实现对 L2 状态的共识(即 L2 的 State Root),同时也作为 L2 txs 的数据存储层,提供 DA(即 batches,类似硬盘的逻辑)。为了提高性能,L2 发送给 L1 的数据是批量的。因此每一个 L2 Block(其实是每一个 L2 Epoch 的 Blocks)都是由一个对应的 L1 Block 驱动产生的。
Rollup Node & Execution Layer
Sequencer 有可能是一个也有可能是共识协议链接的多个节点,目前 OP Stack 仅支持一个 Sequencer。Sequencer 承担了以下职责:
- 直接从 User 获取交易。
- 从 L1 获取存款交易信息 Deposit Txs。
- 打包交易成 L2 的 unsafe blocks,并提供链接到 unsafe blocks 的路径。
- 提交交易到 L1 用于保证 DA。
Sequencer 的作用就是实现快速和低成本的交易打包,并不断派生 L2 区块,保证 L2 Chain 和 L1 Canonical Chain 状态一致。Rollup Node 通过 Sequencer Mode 和 Verifier Mode 实现了 Sequencer 和 Verifier,下面介绍 Sequencer Mode,Verifier 暂不涉及。
Rollup Node 周期性地同步 L1 信息到 L2,本质上就是将 L1 Chain 转换为 L2 Chain,因此如果 L1 链发生了重组(Reorg),L2 也要重新调整。这个同步的过程称为派生 Derivation。**
Rollup Node 之间并没有共识协议,因为它们不需要对某个交易进行共识,而是直接交给 L1 共识完成之后再同步回来。所以 Rollup Node 的状态一致性是由与 L1 之间的同步机制保证的,数据的 Safety 完全是由 L1 保证的(当然 Verifier 需要提供 State Validation),我们可以将 L1 看成一个提供共识 API 的黑盒。
因此 L2 的中心化和去中心化的对于安全性的意义没有 L1 那么大,L1 的去中心化实现了不可篡改性,而 L2 的不可篡改性很大程度已经由 L1 保证了(毕竟状态根在 L1),因此 L2 的所谓中心化只能是影响活性,而不会导致数据变得可以篡改。同时单单谈论 L2 没有意义,而是要谈论 L2 + L1,这本来就是一个整体,所以 L2 的特性应当理解成 L2 + L1 的特性。
L2 的派生 Derivation
Derivation 就是 L2 提案被 L1 共识然后生成 L2 Chain 的过程。因此 Derivation 包括了 L2 Block 状态从 unsafe -> safe -> finalized 状态的转变。具体来说是生成 unsafe Block,之后等待 L1 共识完成后更新为 safe block 和 finalized block。派生也保证了 L2 的 DA 属性,我们随时可以从 L1 Chain 上派生出一条完整的 L2 Chain,因此不必担心 L2 崩溃或项目方跑路而造成资产丢失。
L2 Chain 的派生整体分为两个步骤:
- 生成提案 unsafe block 并发送至 L1。
- 同步 L1 并更新 unsafe block 状态为 safe 或 finalized。
为保证 L2 与 L1 的同步,每个 epoch 的 L2 Blocks 均对应一个 L1 Block,因此 L2 Block 中除了包含用户交易之外,还需要包含 L1 区块的属性,即 l1_info。除此之外,由于 deposit 类型的交易首先发生在 L1,需要包含进每个 epoch 的第一个 L2 Block 中。因此产生 L2 unsafe block 依赖以下三种 Input 参数:
l1_infodepositsuser_txs
上文提到,参与 L2 Block 生成和派生的有两个模块,分别为 Rollup Node 和 Executation Layer,对应 op-node 和 op-geth,我们将 EL 抽离出来,并提供 Engine API 用于承接相关交易的计算。Rollup Node 负责不断从 L1 上同步其最新状态,并构建参与计算的 Payload,然后将 Payload 通过 Engine API 发送给 EL 进行计算,生成最初的 L2 unsafe block 完成创建。
但这只是相当于有了待共识的提案,L2 safe block 的派生需要 Batcher 这些 unsafe blocks 作为 Batches 提交到 L1 上,Rollup Node 从 L1 上收集到这些 Batches 交易后会发送给 EL 进行计算并派生出 safe block 和 finalized block。
此处可能有的疑问是 Batches 不就是当初 Sequencer 中的 Unsafe Blocks 提交上去的吗,为什么还要多此一举的从 L1 上再同步下来?这是因为 L1 作为最终可信的来源,能够保证 Batches 是真实可靠、不被篡改的,而 Sequencer 由于是一个中心化的角色,无法保证这些。
从这个角度依然可以看出,unsafe block 和 safe、finalized Block 地位是不一样的,L2 真正的区块链实际上并不包含 unsafe block,仅包含 safe 和 finalized block 而已。
unsafe block 生成的代码逻辑如下图所示:

- 使用 payload 参数调用 Engine API 的
engine_forkChoiceUpdatedV1接口,这会构建一个 block 的ExecutionPayload,同时会开启一个协程持续从交易池中获取交易并更新ExecutionPayload,并将其发送给 Sequencer。 - 使用
engine_getPayloadV1接口获取第 1 步中构建的ExecutionPayload,并停止其更新的协程。 - 使用
ExecutionPayload调用engine_newPayloadV1接口,这可以构建一个区块,即 unsafe block,并将这个区块插入到 L2 Chain 中。 - 再次调用
engine_forkChoiceUpdatedV1,尝试 finalize 相关区块。通过SetFinalized将我们之前几步产生的block进行Finalized 此方法将一个特定的区块标记为 finalized。
了解了这些后再来看下面的示意图,能够直观的感受到 L2 Chain 是如何被派生出来的。图中,绿色箭头表示 L2 unsafe block 生成的 Input,结合用户交易(橙色箭头),共同构建了 unsafe blocks,并在 epoch 结束时发送到 L1 进行共识,随后通过紫色箭头完成上一个 epoch 中区块的 safe 和 finalized 的变更过程。
Batcher Submit
相比 Plasma 二层网路,Rollup 的优势就是交易数据全部 On Chain 从而保证了 DA,但代价是其吞吐量会受到了 L1 区块空间的制约。因此,上报的交易数据必须经过 L2 的大幅压缩再发送到 L1 上进行存储,这个过程就是由 Batcher 负责的,这也是 Sequencer 进行 L2 Derivation 的重要环节。
L2 的交易数据经过了大幅的压缩,保证体积很小,并发送到了 L1 上一个特定的账户 Batch Inbox 中,此账户并非合约账户,因为只需要数据进行存储无需调用,不需要昂贵的合约账户空间。
交易数据从 L2 到 L1 传递需要经过层层包装,这里涉及如下概念:
- batch:单个 L2 Block 所构建的交易数据称为一个 batch,最终提交到 L1 的是多个 L2 Block 的数据,即 batches。
- channel:一个 Epoch 中多个 batches 的组合成一个 channel,每次 epoch 会发送一个 channel 给 L1。
- frame:channel 由于数据过大可能无法一次性发送,因此将 channel 拆分成多个 frame,分片进行数据传递。
下面这张图描述了交易数据从 L2 到 L1 的不同封装的转换过程,以及 L1 Block 和 L2 Block 的对应关系。
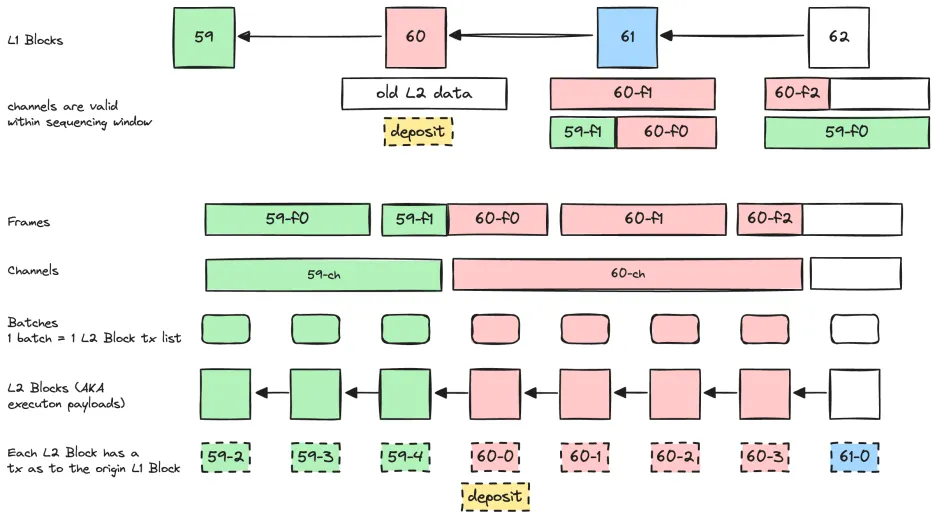
图中有几点值得注意:
- 每个 L2 Epoch Blocks 都包含了一个特殊交易,该交易为 origin L1 Block 的信息。
- 1 个 L2 Block 对应一个 Batch,1 个 Epoch 对应一个 Channel,Channel 是被压缩和编码过的交易数据。
- L2 不同 epoch 的 channels 提交到 L1 区块中时可能是乱序的,但顺序无关紧要,只要在 Sequencing Window 中提交,就会被 L1 区块打包。
这里顺便说一句,L1 交易和 L2 交易的相互同步需要使用 frame、channel、batch 这三个结构,从 L2 -> L1 时是 batch -> channel -> frame,从 L1 Chain 派生 L2 Chain 时是 frame -> channel -> batch。
Proposer Submit
Proposer 负责定时将 L2 的 State Root 上报到 L1 上,这样 L1 就可以掌握 L2 的最新状态,可以对 L2 的数据做一系列验证,这样就可以在 L1 上使用 L2 的相关数据。比如,我们希望在 L1 的某个合约上获取 L2 上 A 账户的余额,那么利用 State Root 验证该账户余额对应的 Merkle Proof 即可,再比如 L1 要验证某个 Withdrawal 交易是否在 L2 上真实存在,也是相同的思路。
虽然 Proposer 和 Batcher 都负责上报 L2 的数据给 L1,但它们上报的区块状态是不同的,Batcher 上报的是 unsafe blocks 的交易内容(压缩后的),目的是保证 DA,并用于派生 L2 Chain,而 Proposer 上报的是 finalized blocks,这是因为只有最终确认的 L2 Block 数据才能被 L1 放心使用,保证不会变更。
L2 Output Proposal
对于 L2 来说,它要利用 L1 共识的部分只有 L2 的状态根哈希,这也称为 L2 派生过程的 Output。L2 Proposer 直接调用 L1 的 L2OutputOracle 合约,周期性的提交 L2 Output 至 L1,同步 L2 的最新状态到 L1,而 Rollup Node 负责实时拉取 L1 中已经 finalized 的 L2 状态。这两部分共同实现了 L1 和 L2 之间的状态数据同步(即 L2 的状态)。如下图。
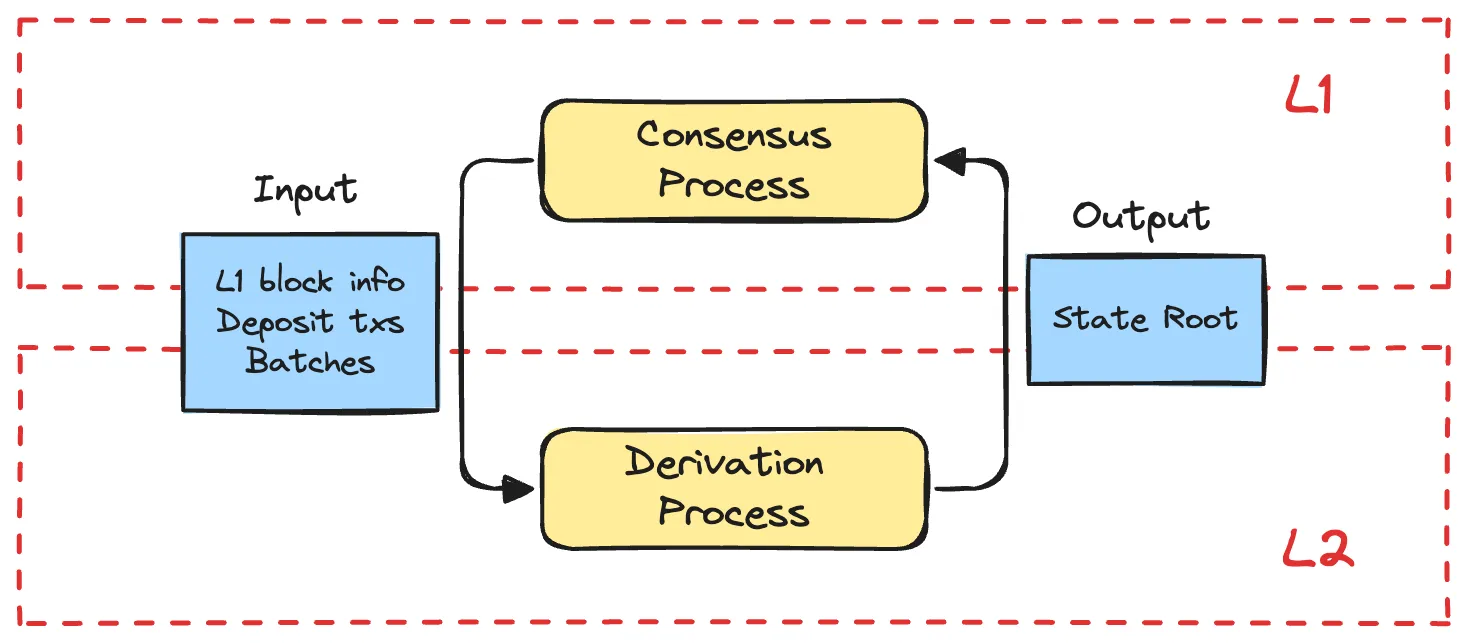
实际上 Output 不仅包括 State Root,其内容如下:
Output Root = state_root || withdrawal_storage_root || latest_block_hash
state_root代表了 L2 中所有账户的状态。withdrawal_storage_root代表了当前提现交易的状态,本身是在 L2toL1MessagePasser 合约账户中,为了方便验证 withdrawal 放入 Output。latest_block_hash用于 L1 判断其拥有的 L2 快是否是最新,从而确定 L2 同步的进度。
Q & A
Q:为什么要把 Deposit Txs 都放到 Epoch 第一个块中,就不能分散到不同的 L2 Blocks 里吗?
A: 要先理解 Sequencing Window 和 Sequencing Epoch。Sequencing Window 是针对 L1 说的,是人为设置的,比如我们设置 10 个 L1 的 块是一个 Sequencing Window,那么这 10 个 L1 的块对应到 L2 上就是一个 Sequencing Epoch,可能是 60 个 L2 的块。
这个逻辑关系很重要,是一个 Sequencing Window 的 l1 块会派生出 derive 一个 epoch 的 L2 块,而不是反过来,为什么?
因为 L2 的块派生时有一个重要的输入为 deposits,depositis 是率先在 L1 上产生的,那么就涉及 L1 上的 deposits 向 L2 同步的问题,那么肯定是一定数量的 L1 (Sequencing Window)块将其 deposits 整合并同步给 L2 Chain,这也就解释了为什么 deposits 一定要在 L2 epoch 中的第一个块中,因为此时 L1 中已经有了 deposits 交易当然要率先放在 L2 的块中越快越好了。
Q:为什么 op-geth 没有集成进 op-node?
A: Optimism Rollup 是一个分层的系统架构,类似于以太坊分为共识层和执行层,Optimism 也在 Rollup 节点中分成了这两个主要的部分。
op-node 是负责 Rollup 协议和共识层的组件。它处理 Optimism 的 Rollup 特有的逻辑,比如从 L1 读取提交的批次数据、验证这些数据,以及管理与 L1 之间的交互。
op-geth 是 L2 的执行环境,专门处理交易的执行和状态的更新。它基于 Geth(go-ethereum)的修改版,专门用于 L2 网络上的交易执行。
分离这两个组件可以带来以下好处:
- 职责分离:op-node 关注 Rollup 协议的运作和 L1 与 L2 之间的桥接逻辑,而 op-geth 专注于 L2 的交易执行。这种设计让每个组件只关注自己的任务,系统更加模块化和清晰。
- 模块化架构:这种分离使得每个组件可以独立更新或优化,而不影响整个系统。优化 Rollup 协议逻辑时,不需要改变执行层,反之亦然。
- 灵活性:不同的 L2 扩容方案或未来可能的执行环境(例如 zk-Rollups)可以替换或扩展 op-geth,而不需要更改 op-node 的逻辑。
在 Optimism 的网络上,op-geth 节点执行 L2 上的交易,维护 L2 的链状态,并通过与其他节点同步来维持分布式网络的运行。op-geth 节点会从 op-node 获取 Rollup 相关的数据,并根据 L2 的链状态执行交易。